
影刀RPA进阶教程:数据库操作MySQL与SQLite读写指南——当Excel不够用了
Excel是个好东西,但一过万行就卡,一过十万行直接崩。
这时候你需要数据库。
MySQL适合多人协作的项目,SQLite适合本地单机。两种都支持,影刀的Python代码指令都能操作。
一、什么时候该换数据库
| 数据量 | 用什么 | 理由 |
|---|---|---|
| < 5000 行 | Excel | 简单直观,够用 |
| 5000 ~ 5万行 | Excel(分sheet) | 还能撑 |
| > 5万行 | SQLite | 本地无安装,文件即数据库 |
| > 10万行 或 多人协作 | MySQL | 并发读写、远程访问 |
另一个触发条件:需要做跨表查询(JOIN)、复杂条件筛选时,SQL比Pandas更简洁。
二、SQLite上手(不需要装任何东西)
店群矩阵自动化突破运营极限!
SQLite是Python自带的,不需要额外安装。
# 在影刀的Python代码指令里直接跑importsqlite3# 创建/连接数据库文件conn=sqlite3.connect(r"D:\\数据\\商品库.db")cursor=conn.cursor()# 建表cursor.execute(""" CREATE TABLE IF NOT EXISTS products ( id INTEGER PRIMARY KEY AUTOINCREMENT, 商品名称 TEXT NOT NULL, 价格 REAL, 销量 INTEGER, 平台 TEXT, 采集时间 TEXT ) """)conn.commit()print("数据库和表已就绪")三、插入数据
单条插入(慢,不推荐批量用)
cursor.execute("INSERT INTO products (商品名称, 价格, 销量, 平台, 采集时间) VALUES (?, ?, ?, ?, ?)",("连衣裙A",128.0,5200,"拼多多","2026-06-09 15:30"))conn.commit()批量插入(推荐)
# 把采集到的数据批量写入data=[("连衣裙A",128.0,5200,"拼多多","2026-06-09"),("T恤男",89.0,3100,"拼多多","2026-06-09"),("运动鞋",299.0,8900,"拼多多","2026-06-09"),]cursor.executemany(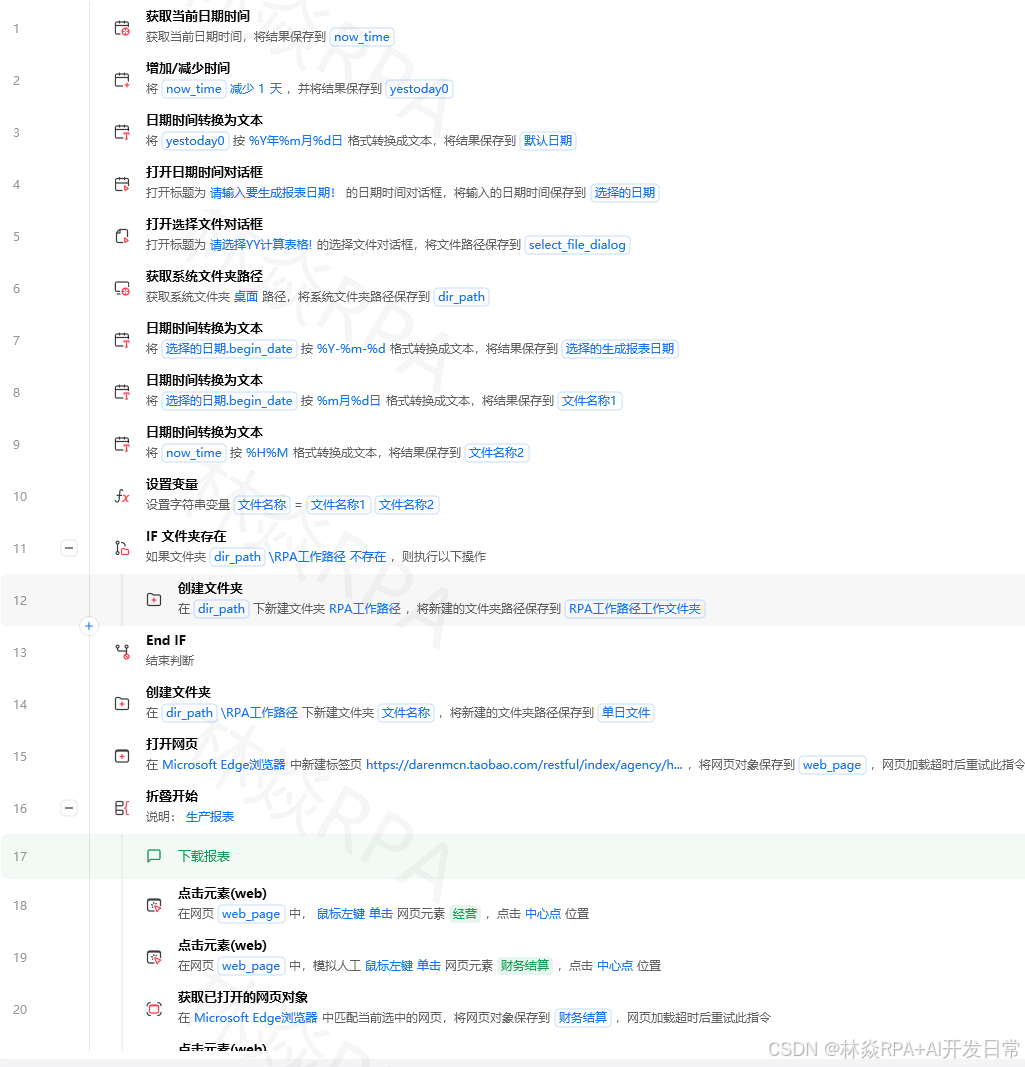"INSERT INTO products (商品名称, 价格, 销量, 平台, 采集时间) VALUES (?, ?, ?, ?, ?)",data)conn.commit()print(f"插入{len(data)}条数据")从Pandas DataFrame直接写入
importpandasaspdimportsqlite3# 假设你有一个采集好的DataFramedf=pd.DataFrame(采集数据)conn=sqlite3.connect(r"D:\\数据\\商品库.db")df.to_sql("products",conn,if_exists="append",index=False)conn.close()print(f"写入{len(df)}条到数据库")if_exists参数:
"append":追加到已有数据后面(最常用)"replace":删掉旧表重建(会丢失历史数据)"fail":如果表已存在就报错
四、查询数据
conn=sqlite3.connect(r"D:\\数据\\商品库.db")cursor=conn.cursor()# 简单查询cursor.execute("SELECT * FROM products WHERE 平台='拼多多' LIMIT 10")rows=cursor.fetchall()forrowinrows:print(row)# 聚合查询cursor.execute(""" SELECT 平台, COUNT(*) as 总数, AVG(价格) as 均价, SUM(销量) as 总销量 FROM products GROUP BY 平台 """)stats=cursor.fetchall()forrowinstats:print(f"平台:{row[0]}, 商品数:{row[1]}, 均价:{row[2]:.2f}, 总销量:{row[3]}")conn.close()读回Pandas DataFrame
importpandasaspdimportsqlite3 conn=sqlite3.connect(r"D:\\数据\\商品库.db")df=pd.read_sql_query("SELECT * FROM products WHERE 价格 < 100 ORDER BY 销量 DESC",conn)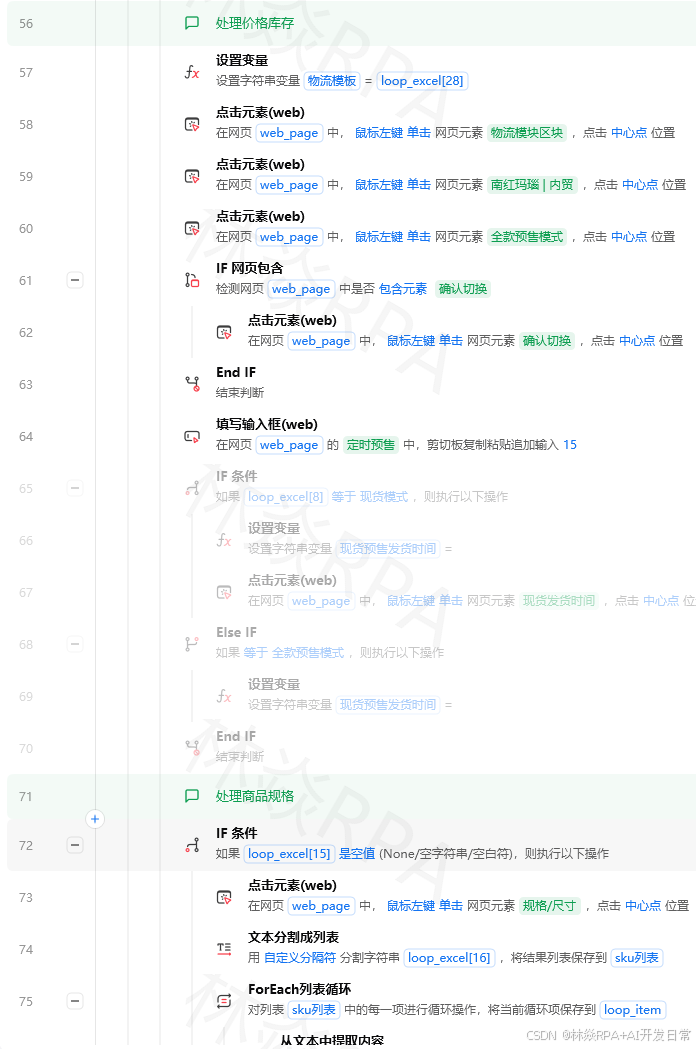conn.close()# 然后可以用Pandas继续处理print(f"低价爆款商品:{len(df)}条")print(df.head(10))五、更新和删除
temu店群自动化报活动案例
conn=sqlite3.connect(r"D:\\数据\\商品库.db")cursor=conn.cursor()# 更新cursor.execute("UPDATE products SET 价格 = ? WHERE 商品名称 = ?",(99.0,"连衣裙A"))# 删除(慎用)cursor.execute("DELETE FROM products WHERE 采集时间 < '2026-01-01'")conn.commit()print(f"影响行数:{cursor.rowcount}")conn.close()六、MySQL连接
MySQL需要安装pymysql或mysql-connector-python包:
# 先在影刀Python图标里搜索安装 pymysqlimportpymysql# 建立连接conn=pymysql.connect(host="192.168.1.100",# 数据库服务器IPport=3306,user="your_user",password="your_password",database="yingdao_data",charset="utf8mb4"# 支持emoji和生僻字)cursor=conn.cursor()# 查询cursor.execute("SELECT * FROM products LIMIT 5")results=cursor.fetchall()# 插入cursor.execute("INSERT INTO products (商品名称, 价格) VALUES (%s, %s)",("商品名",128.0))conn.commit()cursor.close()conn.close()七、在影刀里的标准用法
把数据库操作封装成Python代码模块,通过全局变量和影刀主流程交互:
# Python代码指令:D_数据库操作importsqlite3importpandasaspd conn=sqlite3.connect(r"D:\\数据\\商品库.db")# 1. 从全局变量读取影刀传过来的数据采集结果=全局变量.list_采集数据# 2. 写入数据库if采集结果:df=pd.DataFrame(采集结果)df.to_sql("products",conn,if_exists="append",index=False)print(f"已入库{len(df)}条")# 3. 从数据库查询后写回全局变量df_stats=pd.read_sql_query("SELECT 平台, COUNT(*) as cnt FROM products GROUP BY 平台",conn)全局变量.dict_平台统计=df_stats.to_dict("records")conn.close()作者:林焱
本文为《影刀RPA学习手册》系列文章之一,内容源于实操经验的整理与分享。





