
影刀RPA保姆级教程:影刀与Excel联动深度实战——数据驱动自动化的完整方案
影刀和Excel是最佳搭档。
Excel负责存数据、配参数、记结果;影刀负责读配置、执行操作、写回数据。
两者配合好了,不需要写任何复杂代码,就能搭出一套"数据驱动"的自动化系统。
一、数据驱动是什么意思
一般新手的流程是这样的:
流程里写死:要采集的关键词是"连衣裙"数据驱动的流程是这样的:
Excel里写:关键词 连衣裙 T恤 牛仔裤 流程从Excel里读关键词列表,遍历处理每一个区别在于:改需求时,不用动流程,只需要改 Excel。
这是让自动化可持续运转的关键设计原则。
店群矩阵自动化突破运营极限!
二、Excel 作为配置文件
配置表的标准设计:
Sheet1(任务配置): - 每行一个任务 - 列包含:任务ID、关键词、目标平台、目标URL、是否启用、备注 Sheet2(账号配置): - 每行一个账号 - 列包含:账号ID、平台、手机号、密码、状态 Sheet3(参数配置): - 全局参数 - 列包含:参数名、参数值、说明 - feishu_webhook | https://xxx | 飞书通知地址 - max_retry | 3 | 最大重试次数 - wait_time | 2 | 操作间隔(秒)读取全局参数示例:
读取Excel("D:\自动化配置.xlsx",sheet="参数配置")->参数表# 把参数表转为字典,方便用参数名读取参数字典={}遍历行(参数表):参数字典[当前行['参数名']]=当前行['参数值']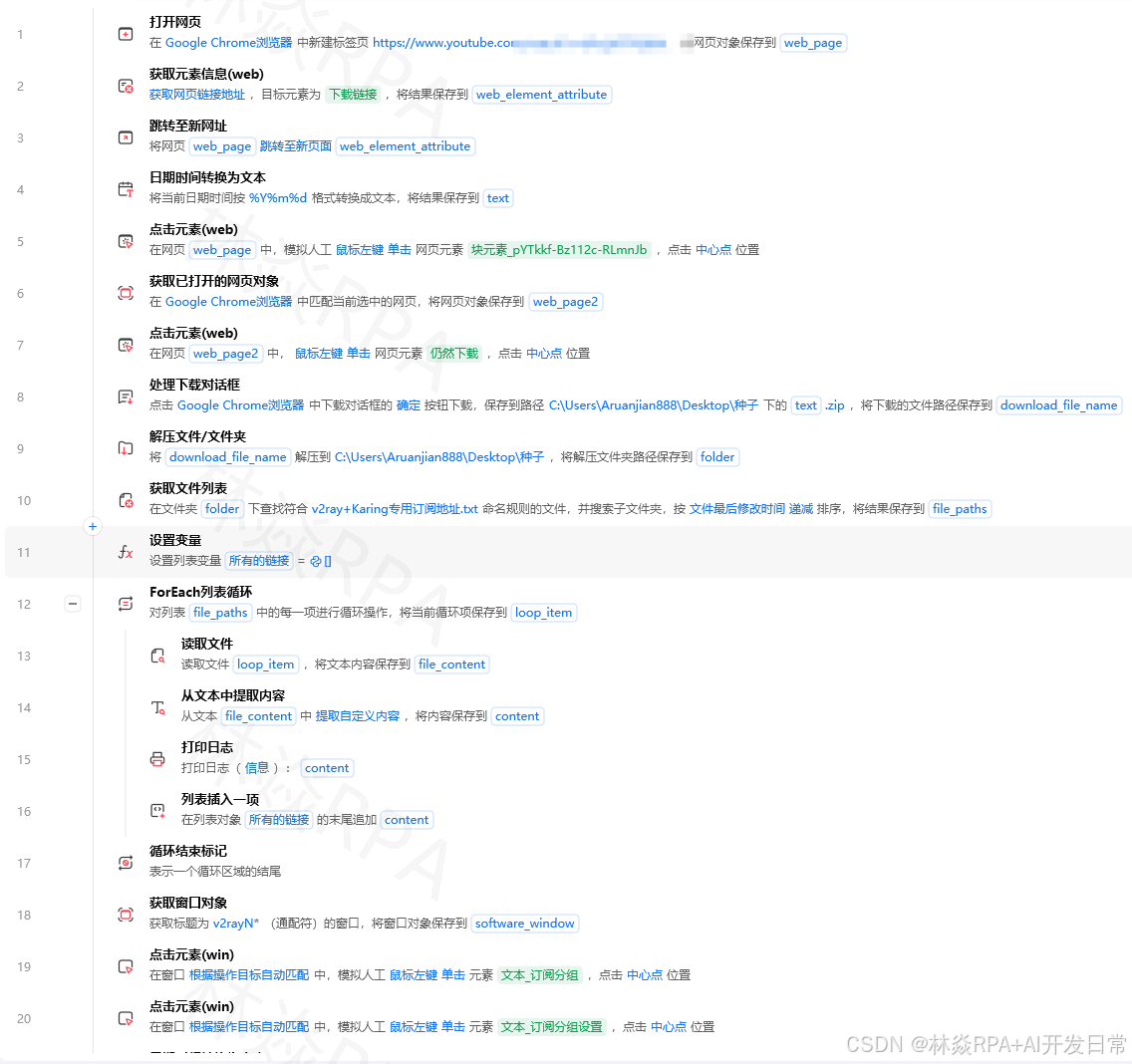# 使用参数webhook=参数字典['feishu_webhook']max_retry=int(参数字典['max_retry'])三、Excel 作为任务队列
批量任务的管理用 Excel 的"执行状态"列来实现:
任务ID | 关键词 | 状态 | 执行时间 | 结果数量 | 备注 T001 | 连衣裙 | 待执行 | - | - | - T002 | T恤 | 执行中 | 2026-06-10 14:30 | - | - T003 | 牛仔裤 | 已完成 | 2026-06-10 14:25 | 120 | - T004 | 卫衣 | 失败 | 2026-06-10 14:20 | 0 | 超时流程逻辑:
读取Excel("D:\任务队列.xlsx")->任务表 遍历行(任务表):如果 当前行['状态']!='待执行':继续下一行# 跳过非待执行的任务任务ID=当前行['任务ID']关键词=当前行['关键词']# 更新状态为"执行中"写入单元格值(任务表,当前行号,'状态','执行中')写入单元格值(任务表,当前行号,'执行时间',当前时间)保存Excel(任务表,"D:\任务队列.xlsx")# 实时保存,断电也有记录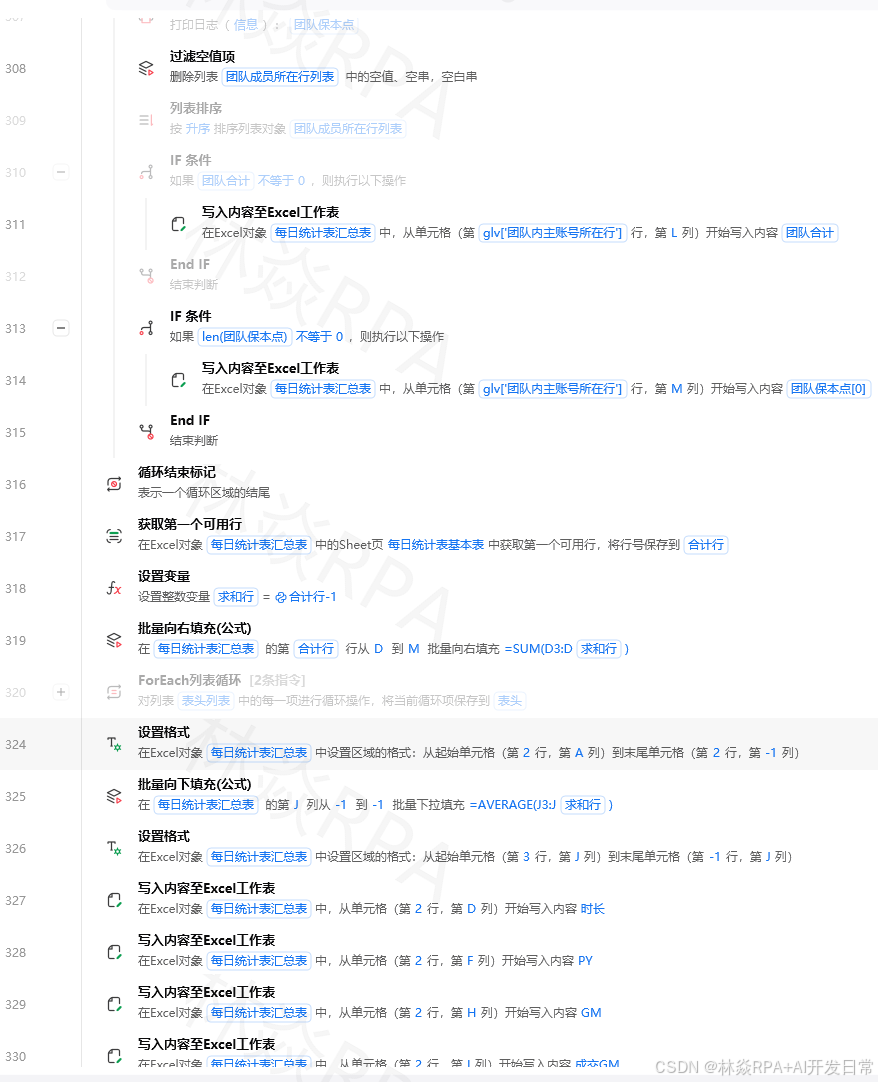[尝试]:结果数量=执行采集任务(关键词)写入单元格值(任务表,当前行号,'状态','已完成')写入单元格值(任务表,当前行号,'结果数量',结果数量)[异常]ase:写入单元格值(任务表,当前行号,'状态','失败')写入单元格值(任务表,当前行号,'备注',str(e)[:50])保存Excel(任务表,"D:\任务队列.xlsx")输出日志("所有待执行任务处理完毕")这样的好处是:流程中断了,下次重启只会处理"待执行"的任务,已完成的不会重复跑。
四、Excel 作为结果存储
采集结果分批写入,不等全部跑完再写:
# 初始化结果文件(每天一个文件)结果文件=f"D:\采集结果\{今日日期}.xlsx"如果 文件不存在(结果文件):新建Excel->结果表 写入行数据(结果表,["采集时间","关键词","商品名","价格","销量","店铺"])导出表格(结果表,结果文件)否则:读取Excel(结果文件)->结果表# 采集循环遍历关键词列表(关键词,当前词):采集数据(当前词)->本批数据 遍历列表(本批数据,一条):写入行数据(结果表,[当前时间,当前词,一条['商品名'],一条['价格'],一条['销量'],一条['店铺']])# 每采集完一个关键词就保存一次,防止中途丢数据保存Excel(结果表,结果文件)输出日志(f"{当前词}采集完成,写入{len(本批数据)}条")五、多 Sheet 操作
一个 Excel 文件里多个 Sheet,分别存不同类型的数据:
# 读取指定 Sheet读取Excel("D:\数据汇总.xlsx",sheet="拼多多")->pdd表 读取Excel("D:\数据汇总.xlsx",sheet="淘宝")->taobao表# 用 Pandas 合并两个 sheet 的数据importpandasaspd df_pdd=pd.DataFrame(pdd表数据)df_tb=pd.DataFrame(taobao表数据)df_pdd['来源']='拼多多'df_tb['来源']='淘宝'df_all=pd.concat([df_pdd,df_tb],ignore_index=True)df_all.to_excel("D:\汇总.xlsx",index=False)六、用 openpyxl 做 Excel 格式化(进阶)
temu店群自动化报活动案例
影刀内置的表格指令够用,但如果需要给结果Excel加颜色、设置列宽,可以在 Python 代码指令里用openpyxl:
fromopenpyxlimportload_workbookfromopenpyxl.stylesimportPatternFill,Font wb=load_workbook("D:\采集结果.xlsx")ws=wb.active# 给标题行加背景色header_fill=PatternFill(start_color="366092",end_color="366092",fill_type="solid")header_font=Font(color="FFFFFF",bold=True)forcellinws[1]:# 第一行cell.fill=header_fill cell.font=header_font# 设置列宽ws.column_dimensions['A'].width=20ws.column_dimensions['B'].width=40ws.column_dimensions['C'].width=15# 给价格异常的行标红(价格<10)red_fill=PatternFill(start_color="FFCCCC",end_color="FFCCCC",fill_type="solid")forrowinws.iter_rows(min_row=2):price_cell=row[2]# 第3列是价格try:iffloat(price_cell.valueor0)<10:forcellinrow:cell.fill=red_fillexcept:passwb.save("D:\采集结果_格式化.xlsx")result="格式化完成"七、Excel 文件的防损坏策略
Excel 文件在写入过程中如果程序崩溃,文件可能损坏。
保护措施:
# 方法1:先写临时文件,写完后重命名保存Excel(结果表,"D:\采集结果_tmp.xlsx")重命名文件("D:\采集结果_tmp.xlsx","D:\采集结果.xlsx")# 方法2:用 Python 做原子写入importos,shutil tmp_path=结果文件+".tmp"df.to_excel(tmp_path,index=False)ifos.path.exists(结果文件):os.replace(tmp_path,结果文件)else:os.rename(tmp_path,结果文件)result="写入完成"八、易错速查
| 问题 | 原因 | 解决 |
|---|---|---|
| 写入数据后打开Excel看不到 | 忘了调"保存Excel"指令 | 每写完一批数据就保存一次 |
| 读取的数字字段是字符串 | Excel 单元格是文本格式 | 读取后 float() 或 int() 转换 |
| 文件被占用,无法写入 | 文件正在用 Excel 打开 | 关掉 Excel,或改为写临时文件 |
| 多次运行结果重复 | 没有清空或追加,而是覆盖 | 明确用"写入行数据"追加 |
| 中文路径报错 | Python 处理路径编码问题 | 路径加 r 前缀或用 os.path.join |
#影刀RPA #Excel自动化 #数据驱动 #RPA与Excel #影刀保姆级教程
作者:林焱
本文为影刀RPA系列文章之一,内容源于实操经验整理与分享。
)

)


