与基于评估驱动的调优)
大多数 RAG 的失败,都是从糟糕的 Chunk(文本分块)开始的。下面将介绍如何切分技术文档,才能避免检索质量被严重破坏。
很多团队会花上数周时间讨论 embedding 模型、向量数据库以及 prompt 设计。结果却把关键运行手册(runbook)粗暴地切成任意的 400-token 小块,然后还疑惑为什么检索效果这么差。
在这些系统里,最先出问题的往往并不是模型本身,而是 Chunk 的边界划分。
之前的文章中,我们已经从整体上梳理了现代 RAG 技术栈的完整链路。现在,我们将深入其中一个会悄悄影响整个下游系统效果的核心子系统。
设想一个面向工程团队的标准内部文档 Copilot 系统。
正确答案也许其实已经存在于知识库(corpus)中,但助手返回的内容却依然不完整。你可以不断调整 prompt、更换 embedding 模型,结果却仍然没有改善。
但如果你真正去查看数据库实际返回的文本,问题往往会立刻变得非常明显。
部署流程(deploy procedure)被拆散到了两个不同的 chunk 中;警告说明(warning)与它所对应的命令被分离;某段代码块虽然被检索出来了,但真正保证其安全可用的解释内容却没有一起被召回。
系统确实找到了“看起来相关”的文本,但这些内容并不足以支撑一个可靠的回答。
Chunking(文本分块)并不仅仅只是一个预处理步骤,它本身就是检索质量的一部分。
你的 Retriever(检索器)实际上并不是在搜索“文档”,而是在搜索“chunks”。
如果你错误地切分了文档,那么模型甚至根本没有机会看到一个完整且连贯的答案。
核心思想:检索作用于 Chunk,而不是文档
大多数人认为他们的 RAG 系统是在搜索文档(docs)。他们会想象数据库正在扫描整个 markdown 文件,以找到正确的页面。但实际发生的事情却完全不同。
索引(index)中存储的是 chunks。Retriever(检索器)评分的是 chunks。Reranker(重排序器)重排的是 chunks。Prompt 接收到的是 chunks。模型基于 chunks 进行回答。
向量数据库只知道你提供给它的那一段具体文本。除非你显式地编程建立这种关系,否则它并不知道这段文本前后还有哪些段落。如果原始文档本身是完全连贯的,但切出来的 chunk 却是一个缺乏上下文的碎片,那么检索质量其实已经受到了破坏。一个糟糕的 chunk,会把一份优秀的文档变成糟糕的证据(bad evidence)。
在比较各种策略之前,我们需要先定义什么才是真正“好的 chunk”。一个好的 chunk 应该保留一个完整且连贯的概念(coherent concept)。它可能是一整套连续的操作步骤,也可能是一段完整的配置说明。它应当确保 warning 与其对应修改的步骤保持在一起。它也应当保留代码示例,以及让该代码真正可用的解释说明。
一个好的 chunk 不应该仅仅为了填满 token 配额而强行合并无关主题。它不应该把一个流程从中间切断。它不应该把命令与 warning 分离,也不应该把示例与上下文拆开。它不应该生成那种必须依赖缺失的相邻 chunk 才能理解的碎片。Chunking 不只是关于大小控制,更重要的是在检索粒度(retrieval granularity)上保留语义与上下文。
主要组块策略
文本切分有几种不同的方法,它们从极其简单到高度复杂不等。我们将逐一分析每种方法的工作机制,以及它们会在什么地方失效。
固定大小切分(Fixed-size chunking)
这是最基础的方法。你每隔 N 个字符或 token 对文本进行切分。也就是读取一段字符串,数到 500,切一刀,然后重复这个过程。
人们使用它,是因为它简单且速度快。几乎所有框架都默认内置了这种方式。对于小说或长篇文章这类结构均匀的文本语料(corpora),只要边界不会明显破坏语义,它有时是可以接受的。当你只是想快速跑通一个原型系统时,它也可以作为一种低成本的基线方案(baseline)。
但它在技术文档(technical docs)中会彻底失效。它会破坏包含大量代码的文档,也会严重破坏带有列表或表格的内容结构。
如果你对部署指南(deployment guide)使用固定大小切分,那么最终几乎必然会出现:命令在一个 chunk 中,而注意事项(caveat)却跑到了下一个 chunk。故障排查流程(troubleshooting flow)会在步骤中间被截断。API 接口说明也可能刚好被切在参数列表和 JSON 返回示例之间。
def chunk_fixed(text: str, size: int = 400, overlap: int = 50) -> list[str]: words = text.split() chunks = [] i = 0 while i < len(words): chunks.append(" ".join(words[i : i + size])) i += size - overlap return chunks这段代码运行速度很快。但它对正在切分的文本结构完全“视而不见”。它只是简单地统计空格,然后切割数组。
如果第 400 个单词刚好位于一个关键数据库密码字符串的中间,它就会直接把这个字符串切成两半。于是 LLM 只拿到半个密码,然后把剩下的一半“脑补”出来。
递归式切分(Recursive chunking)
递归式切分试图变得更“聪明”一些。它不只是单纯统计单词数量,而是会优先按照更大的语义单元进行切分。它会先寻找标题(headings)。如果某个标题下的内容过大,就继续按段落切分。如果段落仍然过大,就再按句子切分。它会沿着这套分隔层级不断向下回退,直到最终生成的 chunk 满足你的大小限制。
这种方式之所以更有效,是因为它比固定大小切分更能保留自然边界。一个段落通常包含一个完整的思想。保持段落完整,会让 chunk 对 LLM 来说更容易理解。
但它依然存在问题,因为像标题这样的结构标记(structural markers)并不一定能够完整表达真正的语义单元(semantic unit)。文档本身可能结构混乱。很多人在编写 markdown 时,标题层级并不一致。某些本应关联在一起的重要内容,如果所在章节过长,依然可能被拆开。
它依然比固定大小切分更适合作为默认方案。当你还没有针对特定文档类型构建真正的结构感知(structure-aware)解析能力时,它可以作为一个不错的基线方案(baseline)。
import redef chunk_recursive(text: str, max_tokens: int = 512) -> list[str]: separators = [ r"\n#{1,6}\s", # headings r"\n\n", # paragraphs r"(?<=\.)\s", # sentences ] return _split_recursive(text, separators, max_tokens)def _split_recursive(text: str, seps: list[str], max_t: int) -> list[str]: if len(text.split()) <= max_t or not seps: return [text.strip()] if text.strip() else [] parts = re.split(seps[0], text) chunks = [] for p in parts: if len(p.split()) <= max_t: chunks.append(p.strip()) else: chunks.extend(_split_recursive(p, seps[1:], max_t)) return [c for c in chunks if c]这种逻辑会尽量尊重作者原本的段落划分。它通过正则表达式(regular expressions)寻找文本中的自然停顿位置。但它依然并不真正理解文本本身的含义。
语义切分(Semantic chunking)
语义切分采用了一种不同的方法。它不是基于固定大小或标点符号进行切分,而是根据主题或语义的变化来决定边界。
典型的实现方式,是先将文本拆分成单独的句子。然后为每一句话计算 embedding 向量。接着,它会比较相邻句子之间的余弦相似度(cosine similarity)。当相似度低于某个阈值时,它就会认为主题发生了变化,并在那个位置创建一个 chunk 边界。
这种方式的优势在于,它能够更好地保留连贯的语义。它减少了随意的文本碎片化问题。如果作者用一大段文字持续讨论某个特定的数据库迁移(database migration),语义切分会尽量将这些内容保留在同一个 chunk 中。而当作者开始转向讨论缓存失效(cache invalidation)时,chunker 就会在那里进行切分。
但它的代价也非常明显。由于你必须为整个语料库中的每一句话都计算 embedding,仅仅为了确定该在哪里切分,因此它的运行成本要高得多。
如果你的知识库包含一百万个句子,那么在真正开始索引 chunk 之前,你就已经需要向 embedding 服务提供商发起一百万次 API 调用。
因此,它的构建复杂度也会高得多。由于边界是由一个“黑盒” embedding 模型决定的,而不是显式规则,所以如果缺乏评估(evaluation),你会很难理解它为什么这样切分。
它最适合用于那些“知识密集型”(knowledge-heavy)的语料库,也就是主题边界比文档布局本身更重要的场景。
比如法律合同(legal contracts)或长篇研究报告(long-form research reports)——这些文档可能只是普通纯文本格式,但其中的思想与主题却会频繁切换。
结构感知切分(Structure-aware chunking)
结构感知切分会显式利用文档结构。它会解析标题(headings)、子标题(subheadings)、编号步骤(numbered procedures)、代码块(code blocks)、表格(tables)、提示框(callouts)以及 warning 等结构元素。
它非常适合技术文档(technical documentation)。因为它能够保留用户在提出技术问题时真正需要的完整信息单元。它的一种典型应用场景,就是处理 GitHub Wiki 或内部开发者门户(internal developer portal)。
如果你有一个 markdown 文件,结构感知型 chunker 会知道:以> **Warning**开头的内容块,与它前面的段落之间存在关键关联。它也知道:使用三重反引号(triple backticks)包裹的代码块绝不应该从中间被切开。
它的代价在于,它高度依赖解析器(parser)的质量。你需要针对不同格式编写定制化实现。用于 Markdown 的结构感知 chunker,与用于 HTML 或 PDF 的实现方式会有很大不同。
HEADING = re.compile(r"^(#{1,6})\s+(.+)$", re.MULTILINE)_CODE = re.compile(r"```[\s\S]*?```")_WARNING = re.compile(r"^>\s*\*\*(Warning|Note|Caution)\*\*.*", re.MULTILINE)from dataclasses import dataclass@dataclassclass Chunk: content: str heading_path: list[str] doc_id: str meta: dict has_code: bool = False has_table: bool = Falsedef chunk_structured(text: str, max_tokens: int = 512) -> list[Chunk]: parts = _HEADING.split(text) chunks = [] stack = [] if parts[0].strip(): chunks.append(Chunk( content=parts[0].strip(), heading_path=[], doc_id="", meta={}, has_code=bool(_CODE.search(parts[0])), )) for i in range(1, len(parts) - 1, 3): level = len(parts[i]) title = parts[i + 1].strip() body = parts[i + 2].strip() if i + 2 < len(parts) else "" if not body: continue while stack and stack[-1][0] >= level: stack.pop() stack.append((level, title)) path = [h[1] for h in stack] sections = _split_preserving_warnings(body, max_tokens) for sec in sections: chunks.append(Chunk( content=sec, heading_path=path, doc_id="", meta={}, has_code=bool(_CODE.search(sec)), has_table=bool("|" in sec and "---" in sec), )) return chunksdef _split_preserving_warnings(text: str, max_t: int) -> list[str]: paras = [p.strip() for p in text.split("\n\n") if p.strip()] merged = [] i = 0 while i < len(paras): block = paras[i] while i + 1 < len(paras) and _WARNING.match(paras[i + 1]): block += "\n\n" + paras[i + 1] i += 1 merged.append(block) i += 1 result = [] buf = [] buf_t = 0 for m in merged: t = len(m.split()) if buf and buf_t + t > max_t: result.append("\n\n".join(buf)) buf = [] buf_t = 0 buf.append(m) buf_t += t if buf: result.append("\n\n".join(buf)) return result这段代码会跟踪标题路径(heading path)。如果它从文档深层提取出一个段落,它会记住这个段落属于“Deploy Guide -> Prerequisites -> Network Config”这一层级结构。
当我们后面讨论 metadata(元数据)时,你会看到为什么这一点非常重要。
它还会主动识别 warning,并将 warning 与前面的文本块绑定在一起。
Overlap:它什么时候有帮助,什么时候反而有害
Overlap(重叠)是 RAG 中最容易被误用的参数之一。大多数教程都会告诉你,把 chunk size 设置为 500,overlap 设置为 50。很多人直接照抄这个配置,然后再也不会去思考它。
Overlap 的存在,是为了在 chunk 边界附近保留上下文(context)。
如果一句话刚好被从中间截断,或者下一个 chunk 中的代词(pronoun)指向前一个 chunk 中的某个名词,那么 overlap 可以为 embedding 模型提供足够的上下文,让它理解正在发生什么。
它本质上像是一个在文本上滑动的窗口(sliding window)。
它对于那些无法放进单个 chunk 的长流程(long procedures)非常有帮助。它也适用于“代码 + 解释”这种组合内容。对于那些上下文会影响含义的版本相关说明(version-sensitive instructions),overlap 同样有价值。
但 overlap 同样也经常带来负面影响。
它会在 Top-K 检索结果中生成大量几乎相同的 chunk。
如果 overlap 设置过大,而用户又搜索某个特定术语,那么向量数据库可能会返回三个彼此 80% 内容相同的 chunk,因为它们之间存在大量重叠。
这会让检索结果被重复内容污染(pollute retrieval with repetitive evidence)。它会浪费你的上下文预算(context budget),同时让最终呈现给用户的引用(citations)变得嘈杂且重复。
Overlap 并不是“免费的上下文”。
它本质上是 recall(召回率)与 precision(精确率)之间的一种严格权衡(tradeoff)。
过大的 overlap,通常只是对糟糕 chunking 的一种“创可贴式修补”(band-aid)。
如果你能够在语义边界(semantic boundaries)上智能地切分文本,那么你实际上只需要非常少的 overlap。
Metadata(元数据)与 Chunking 是绑定在一起的
每个 chunk 都应该携带 metadata(元数据)。
它需要包含源文档名称,以及我们之前提取出来的标题或章节路径(heading / section path)。它还需要包含文档类型(doc type)、服务名称(service name)、版本号(version)、更新时间戳(updated timestamp),以及所属负责人或团队(owner / team)。
之所以重要,是因为:结合过滤(filtering)的检索,会明显提升 retrieval 效果。
如果用户问:“如何部署 payment service”,你不应该只依赖向量相似度(vector similarity)。
你应该先对向量数据库增加过滤条件,例如:
service_name == "payment"然后再执行余弦相似度(cosine similarity)搜索。
像 Pinecone 或 Qdrant 这样的现代向量数据库,大多数都允许你在查询向量的同时附加 metadata filters(元数据过滤条件)。
这样可以缩小搜索空间(search space),并过滤掉大量无关结果(irrelevant hits)。
带有上下文信息的 reranking(重排序)效果也会更好。
如果 reranker 模型能够看到附带在文本上的 heading path(标题路径),那么它就能理解一个“普通段落”到底处于什么上下文之中。
对于最终用户来说,引用(citations)也会变得更容易理解。
同时,过期内容(stale content)也会更容易被检测并过滤掉。
一个没有 metadata 的 chunk,本质上只是漂浮的文本(floating text)。
它没有任何现实中的锚点(anchor in reality)。
当你把 chunk 传递给 LLM 时,你不应该只传原始文本(raw text)。
你应该像下面这样进行格式化:
Source: payment-api-runbook.mdSection: Deploy Guide > PrerequisitesLast Updated: 2026-02-15Ensure kubectl access and DEPLOY_TOKEN is set.> **Warning** Without DEPLOY_TOKEN the deploy will silently fail. ```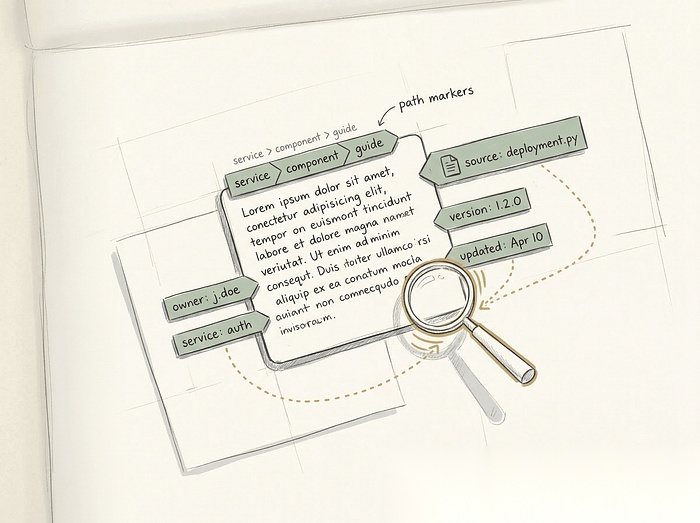 这样做,可以为 LLM 提供它生成“有依据且准确回答”(grounded, accurate answer)所需要的上下文。 同时,它也为 LLM 提供了生成正确引用(citation)所需的精确字符串,使模型能够在回答结尾写出合适的引用来源。 Chunking 失败在生产环境中是如何表现出来的 ------------------------- 当你构建这些系统时,你会开始识别出坏 chunking 的一些典型症状。它们通常会表现得像是模型失败。 最常见的一种情况是“好像对,但又不完全对”的回答。被检索到的 chunk 在主题上相关,但在实际操作层面并不足够。用户询问如何配置 timeout。LLM 解释了 timeout 的作用,但遗漏了具体的 YAML 语法,因为那部分内容位于下一个 chunk 中。 然后是“缺失最后一步”的问题。回答解释了大部分流程,却遗漏了最后那个关键命令或 warning。用户照着操作后,把自己的环境搞坏了。 “过期答案(stale answer)”问题,则发生在旧版本文档中的 chunk 排名高于当前版本的时候。向量相似度(vector similarity)并不理解时间。一份介绍如何配置旧版系统的老文档,可能因为与用户查询有更高的关键词重叠,而排在新版、更加精简的文档前面。 你还会看到一些“看起来真实但实际上没什么用”的 citations(引用)。回答引用了一个只部分支持其结论的 chunk。用户点击 citation 链接,阅读对应段落后,会发现里面其实并没有 LLM 提供的那个具体命令。剩余部分,是因为 chunk 不完整,LLM 基于训练数据自行 hallucinate(幻觉生成)出来的。 “巨大块(giant-clump)失败”会在你把 chunk size 设置得过大时出现。chunk 大到 retrieval 从技术上来说仍然有效,但 prompt assembly(Prompt 拼装)的效果被稀释了。LLM 会被周围 1000 个 token 的无关文本干扰,而真正重要的可能只有其中 50 个 token,于是回答质量开始下降。 “微小碎片(tiny-fragment)失败”则完全相反。chunk 小到模型不得不脑补缺失的上下文。它看到一个只写着 `docker-compose up -d` 的 chunk,然后围绕它编造出完整的叙事逻辑。 很多“模型失败”,实际上都是 chunk 设计失败。你无法靠 prompt engineering 去修复已经损坏的 evidence(证据)。 基于评估驱动的 Chunk 调优(Eval-driven chunk tuning) ------------------------------------------ 这就是工程化方法真正发挥作用的地方。 RAG 开发中的一种反模式(anti-pattern)是:只选择一次 chunk size,随机添加 overlap,从不检查被检索到的 evidence,然后凭感觉调参数。你修改一个设置,问 bot 一个问题,看起来似乎还可以,然后就直接上线(push to prod)。 真正的工程化方法,是建立一个小型评估集(evaluation set),并系统性地比较不同的 chunking 策略。 你需要评估 retrieval 命中质量。Top 3 chunks 是否真正包含了答案?你需要评估回答完整性。LLM 是否拥有足够上下文来生成完整回答?你还需要检查 citation 的有效性与 chunk 的连贯性(coherence)。你需要观察 chunking 策略如何处理歧义(ambiguity)以及对过期文档的敏感性(stale-doc sensitivity)。 你并不需要成千上万个问题。你需要的是一个经过精心筛选的 50 到 100 个问题集合,它们能够代表真实用户意图(real user intent)。 建议的评估集(eval set)类别包括:精确查找类问题,例如“API 的最大 timeout 是多少?”;流程执行类问题,例如“如何回滚数据库迁移(rollback a database migration)?”;故障排查类问题,例如“为什么 auth service 会返回 502?”;此外,版本敏感型问题与配置类问题同样重要。 然后,你使用这套评估集运行不同的 chunking 策略。你比较 fixed-size、recursive 与 structure-aware。你测试不同的 chunk size 与 overlap 水平。你测试带 metadata-aware filters 与不带 metadata-aware filters 的效果差异。 ```plaintext from dataclasses import dataclass@dataclassclass EvalCase: question: str expected_chunk_contains: str category: str def eval_chunking( text: str, cases: list[EvalCase], strategies: dict[str, callable], embed_fn: callable, search_fn: callable, top_k: int = 3,) -> dict[str, dict]: results = {} for name, chunk_fn in strategies.items(): chunks = chunk_fn(text) contents = [c.content if hasattr(c, 'content') else c for c in chunks] chunk_embs = embed_fn(contents) hits = 0 total = len(cases) for case in cases: q_emb = embed_fn([case.question])[0] idxs = search_fn(q_emb, chunk_embs, top_k) retrieved = [contents[i] for i in idxs] if any(case.expected_chunk_contains in r for r in retrieved): hits += 1 results[name] = { "hit_rate": hits / total if total else 0, "num_chunks": len(chunks), "avg_tokens": sum(len(c.split()) for c in contents) // max(len(contents), 1), } return results这种方法能够让你真正验证哪种策略有效。
search_fn用来模拟你的向量数据库。top_k参数则模拟你计划放入 LLM prompt 中的 chunk 数量。
你可能会发现:对于流程类问题(procedural questions),structure-aware chunking 能够将命中率从 60% 提升到 85%。
Chunking 应该通过经验评估(empirically)来调优,而不是直接继承某篇博客里的默认参数配置。
一个实用的默认策略
如果你现在正在构建一个系统,并且希望有一个强有力的起点,那么下面是一套针对技术文档(technical docs)的推荐默认方案。
从 structure-aware recursive chunking(结构感知递归切分)开始。编写一个能够适配你特定 markdown 或 HTML 风格的 parser(解析器)。将标题、代码块、warning 以及操作流程(procedures)保留为不可拆分的原子单元(atomic units)。
使用轻量 overlap。不要使用过大的 overlap。如果你的 chunks 在语义上已经足够连贯,那么你只需要极少量 overlap 来覆盖边界情况(edge cases)。
为每个 chunk 附加丰富的 metadata(元数据)。将 heading path(标题路径)直接注入到文本 payload 中,让 embedding 模型能够看到它。
在你更换 embedding 模型或向量数据库之前,先评估这套 baseline(基线方案)。它对于真实工程文档来说已经足够强大,同时实现复杂度也足够低,不需要你构建一个庞大的研究项目。
一个很重要的细节是:不同类型的文档,可能依然需要不同的 chunking 规则。
对整个 corpus(语料库)统一采用同一种 chunking 策略,往往是一个错误。
Slack 消息记录(Slack message dump)所需要的切分逻辑,与正式 API 文档(formal API specification)是完全不同的。
配套工具包(Artifact pack)
为了让这些内容真正具备可执行性,下面是一份 Chunking Tuning Checklist(Chunking 调优检查清单),你可以在部署下一版 pipeline 之前逐项检查。
- • 我们是否保留了语义边界(semantic boundaries)?
- • warning 是否与其对应修改的命令保留在一起?
- • 代码块是否与其解释内容保留在一起?
- • 每个 chunk 是否都携带了有价值的 metadata(来源、标题路径、版本号)?
- • 我们是否是在有意识地使用 overlap,而不是盲目添加?
- • 我们是否已经基于真实问题评估过 chunking 策略?
- • 在调试过程中,我们是否真正检查了被检索出来的文本,而不仅仅只是观察最终的 LLM 输出?
本文中提供的代码片段,已经构成了一个可靠 chunking pipeline 的基础。
你可以直接使用这个 structure-aware chunker,针对你的文档格式调整其中的 regex(正则表达式),然后通过 eval harness(评估框架)来验证它是否真正有效。
结论
Chunk 是系统进行推理时最基础的 evidence unit(证据单元)。
如果这个单元本身是不连贯的,那么 retrieval quality(检索质量)就会在不知不觉中崩塌。
好的 chunking,会让整个 RAG pipeline 后续的所有环节都变得更容易。
糟糕的 chunking,则会迫使后面的每一个组件,都去补偿已经损坏的 evidence。
在你更换模型之前,在你升级向量数据库之前,尤其是在你开始构建复杂 multi-agent loops(多 Agent 循环系统)之前,先看看你的数据。
确保你的 chunks 真正具备意义。
接下来是什么
我们已经修复了基础层。现在,我们的文档已经成为连贯且可检索的 evidence units(证据单元)。
但要真正找到正确的 chunks,仅靠向量相似度(vector similarity)还远远不够。
在后面的文章中,我们或将讨论 Hybrid Search(混合检索)。
可能会详细拆解:
什么时候 BM25 关键词检索(keyword search)会优于向量检索(vector search);
什么时候向量检索更占优势;
以及如何在不破坏延迟(latency)的前提下,正确地将两者结合起来。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋
📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
)



